فرض کنید یک مهمانی ترتیب داده شده و صدها نفر که همدیگر را نمیشناسند در آن
مهمانی به صرف عصرانه دعوت شدهاند [1]. بهتدریج جمعهای دو و سه نفری شکل میگیرد
و مهمانان مشغول گفتوگو و معاشرت میشوند. به یکی از مهمانان (ماری) اطلاع داده
میشود که یکی از نوشیدنیها متمایز از بقیه است و بسیار باکیفیتتر و گرانقیمتتر
است. اگر آن فرد موضوع را صرفاً با همان چندنفری که میشناسد در میان بگذارد، هنوز
آن نوشیدنی گرانقیمت حفظ میشود.
مهمانها بهتدریج باهم ملاقات میکنند و جمعهای جدید میسازند. میتوانیم فرض
کنیم آنها با مسیرهایی فرضی به همهکسانی که تاکنون ملاقات کردند وصل هستند. مثلاً
جان هنوز با ماریا ملاقات نکرده، ولی هردو با مایک ملاقات کردهاند، پس یک مسیر
نامرئی از جان به ماری وجود دارد که از مایک میگذرد. بهمرور زمان چنین پیوندهای
فرضیای بین جمعیت شکل میگیرد. راز نوشیدنی خاص از طریق ماری به جان و سپس از جان
به مایک منتقل میشود، خبر بهسرعت در حال پخش شدن است.
وقتی خبر به همه برسد، همه از آن نوشیدنی خاص برمیدارند. اگر هر ملاقات
میهمانان باهم فقط 10 دقیقه زمان ببرد، در کل 16 ساعت طول میکشد تا هر مهمان با
بقیه 99 نفر ملاقات کند. بنابراین منطقاً میتوان امیدوار بود که بعد از اتمام
مهمانی حداقل چند قطرهای از نوشیدنی خاص باقی بماند.
در این فصل نشان میدهیم چرا این تصور درست نیست. خواهیم دید که این میهمانی با
مدلی کلاسیک در علم شبکه به نام مدل تصادفی شبکه قابل مدل کردن است . و نظریه شبکه
تصادفی به شما میگوید برای اینکه نوشیدنیتان به خطر بیفتد، نیازی نیست حتماً هر
فرد با همه افراد دیگر ملاقات کند و آنها را بشناسد. درواقع بهمحض اینکه فردی
حداقل یک مهمان دیگر را ملاقات کند شبکهای پدید میآید، که اجازه میدهد اطلاعات
به همه برسد. بنابراین در زمان اندکی، همه از آن نوشیدنی بهرهمند شدهاند.
شکل3-1 از مهمانی عصرانه تا شبکههای تصادفی
شکلگیری شبکه آشنایان از طریق برخوردهای تصادفی در یک مهمانی عصرانه.
در اوایل مهمانی، گروههای منفرد تشکیل میشوند.
بهتدریج اشخاص باهم معاشرت میکنند و یک شبکه نامرئی شکل میگیرد که همه
آنها را به یک شبکه متصل میکند.
بخش 3-2
مدل تصادفی شبکه
هدف علم شبکه این است که مدلهایی بسازد که نمایانگر ویژگیهای شبکههای واقعی
باشد. در بیشتر شبکههای واقعی، نظم مشخصی که در شبکه بلورهای کریستال یا تارهای
عنکبوت وجود دارد، دیده نمیشود و در نگاه اول به نظر میرسد که آنها کاملا تصادفی
و در هم پیچیدهاند (شکل
2.4). نظریه شبکه تصادفی، از طریق ساخت و توصیف شبکههای واقعا تصادفی ، ویژگی
تصادفی بودن آشکار را در بر میگیرد.
ازنقطهنظر مدلسازی، شبکه موجودیتی نسبتاً ساده است که تنها شامل گره و پیوند
میشود. چالش واقعی آنجاست که چطور تصمیم بگیریم بین چه گرههایی پیوند ایجاد کنیم
تا پیچیدگی یک سیستم واقعی را مدل کرده باشیم. با توجه به این موضوع یک شبکه تصادفی
ساده از فلسفه سادهای برخوردار است: سادهترین راه نیل به این هدف این است که به
صورت تصادفی بین گرهها پیوند ایجاد شود، به این ترتیب یک شبکه تصادفی ایجاد
میشود: (نکته 3-1)
یک شبکه تصادفی شامل N گره است، که هر جفت گره با احتمال p به هم پیوند
خوردهاند..
برای ساختن یک شبکه تصادفی مراحل زیر را طی میکنیم:
با N گره منفرد شروع میکنیم
یک جفت گره را انتخاب کرده و عدد تصادفی بین 0 و 1 تولید میکنیم. اگر عدد
تصادفی از p بیشتر بود، دو گره را با یک پیوند به هم وصل میکنیم در غیر این
صورت آنها را وصل نمیکنیم.
مرحله 2 را برای همه N(N-1)/2 جفت گره ممکن تکرار میکنیم.
شبکهای که بعداز این فرایند به دست میآید گراف تصادفی یا شبکه تصادفی نامیده
میشود. دو ریاضیدان به نامهای پال اردوش و آلفرد رنی نقش مهمی در شناخت خواص این
شبکهها بازی کردهاند و به احترام آنها شبکه تصادفی، شبکه اردوش-رنی نامیده
میشود. (نکته 3-2)
بخش 3-3
تعداد پیوندها
به شکلهای مختلف میتوان یک شبکه تصادفی با پارامترهای N و p مشابه ایجاد کرد
که به هر یک از آنها یک تحقق گفته میشود(شکل
3.3). هر یک از این تحققها با شبکه دیگری که دقیقا با همین پارامترها ساخته
میشود، نهتنها در شکل ترسیمی حاصل از پیوندها، بلکه در تعداد پیوندها نیز فرق
میکند؛ بنابراین چنانچه بتوانیم تعداد پیوندهای مورد انتظار برای یک شبکه تصادفی
با پارامترهای ثابت N و p را به دست آوریم، بسیار مفید خواهد بود.
احتمال اینکه یک تحقق از یک شبکه تصادفی دقیقاً تعداد L تا پیوند داشته باشد،
حاصلضرب سه عبارت زیر است:
احتمال اینکه L دفعه تلاش برای ایجاد پیوند بین همه N(N-1)/2 جفت گره، به
ایجاد پیوند منجر شود که این مقدار برابرpL است.
احتمال اینکه بقیه N(N-1)/2 – L تلاش به ایجاد پیوند منجر نشود که مقدار
این احتمال برابر است با (1-p)N(N-1)/2-L
3. یک عامل ترکیباتی,
که تعداد حالاتی را میشمارد که میتوان L پیوند را از بین N(N-1)/2 جفت گره
انتخاب کرد.
بنابراین احتمال اینکه یک شبکه تصادفی با پارامترهای مذکور دقیقاً L پیوند داشته
باشد عبارت است از:
ازآنجاکه فرمول (3-1) یک توزیع دوجملهای است (نکته 3-3) تعداد پیوندهای مورد
انتظار در یک گراف تصادفی برابر است با:
\
بنابراین عبارت است از ضرب احتمال پیوند میان دو گره یا p، در تعداد
جفتهایی که سعی میکنیم به هم وصل کنیم، ، که حداکثر برابر است با Lmax
= N(N - 1)/2 (فصل 2).
با استفاده از رابطه (3-2) ما درجه متوسط یک شبکه تصادفی را به دست میآوریم:
بنابراین < k > عبارت است از حاصلضرب احتمال پیوند میان دو گره یا p، در N-1
، حداکثر تعداد پیوندهایی است که یک گره میتواند در شبکهای بهاندازه N داشته
باشد.
بهطور خلاصه تعداد پیوندها در یک شبکه تصادفی بین هر تحقق متفاوت است. و مقدار
مورد انتظار آن بهواسطه N و p به دست میآید. اگر p را افزایش دهیم، گراف چگالتر
میشود: تعداد متوسط پیوندها بهصورت خطی از L >=0> تا Lmax و
درجه متوسط یک گره هم از k >=0> تا k >=N-1> افزایش می¬یابد.
شکل 3-3 شبکههای تصادفی، شبکههای واقعا تصادفی هستند
ردیف بالا
سه نمونه تحقق از یک شبکه تصادفی که با پارامترهای یکسان p=1/6 و N=12 تولید
شدهاند. بهجز پارامترهای مشخصشده، شبکهها نه نهتنها متفاوت به نظر میرسند،
بلکه تعداد پیوندهایشان شان نیز متفاوت است (L=10,10,8).
ردیف پایین
سه نوع تحقق از یک شبکه تصادفی با p=0.03 و N=100. چندین گره از درجه k=0 هستند، که
بهعنوان گرههای ایزوله منفرد در پایین گراف نمایش داده شدهاند.
بخش 3-4
توزیع درجه
در یک تحقق داده شده از یک شبکه تصادفی برخی گرهها پیوندهای متعددی دریافت
میکنند درحالیکه بعضی گرههاو برخی دیگر یا پیوندهای کمتری دریافت میکنند یا
اصلا پیوندی دریافت نمیکنند (شکل
3-3). این تفاوتها با توزیع درجه یا pk بیان میشود که
برابر است با احتمال اینکه یک گرهای که بطور تصادفی انتخاب شده از درجه k داشته
باشد. در این بخش ما pk را برای شبکه تصادفی به دست آورده و
درباره خواص آن بحث میکنیم.
شکل 3-4 مقایسه توزیع درجه دوجملهای و پوآسون
فرم دقیق توزیع درجه یک شبکه تصادفی توزیع دوجملهای است (نصف نصفنیمه سمت چپ).
برای < N >> < k توزیع دوجملهای بهخوبی توسط بوسیله توزیع پوآسون تخمین زده
میشود (نیمه سمت راست). ازآنجاکه هر دو فرمول یک توزیع مشابه را توصیف میکنند،
ویژگیهای یکسانی دارند: توزیع دوجملهای به p و N وابسته است، درحالیکه توزیع
پوآسون تنها یک پارامتر < k > دارد. توزیع پوآسون محاسبات را ساده سادهتر میکند و
از این جهت ترجیح دارد.
توزیع دوجملهای
در شبکه تصادفی، احتمال اینکه گره i دقیقاً از درجه k باشد، حاصلضرب سه عبارت
زیر است [15]:
احتمال اینکه k تا از پیوندهای آن تشکیلشده باشند، یا pk
احتمال اینکه بقیه N-1-k پیوند دیگر تشکیل نشده باشند، یا (1-p)N-1-k
تعداد حالاتی که میتوانیم k پیوند را از بین N-1 پیوندی که یک گره
میتواند داشته باشد انتخاب کنیم، یا
متعاقباً توزیع درجه یک شبکه تصادفی نیز از توزیع دوجملهای پیروی میکند
شکل این توزیع به اندازه سیستم، N و احتمال p بستگی دارد (شکل
3-4). با کمک توزیع دوجملهای (جعبه نکته 3-3) اجازه میدهدمیتوانیم تا درجه
متوسط شبکه یعنی را اندازهگیری کنیم، (رابطه 3-3) را بازیابی کنیم بازیابی
کنیم (رابطه 3-3)، و به همین ترتیب مومنت درجه دوم و واریانس σ_k آنها
حساب کنیم (شکل
3-4).
توزیع پوآسون
بیشتر شبکههای واقعی تنک هستند، بدین معنی که برای آنها k > << N> است (جدول
2-1). با این محدودیت، توزیع درجه (رابطه 3-7) با توزیع پوآسون (مباحث پیشرفته
3-A) تخمین زده میشود.
که به همراه رابطه (3-7)، توزیع درجه شبکه تصادفی نامیده میشوند.
توزیع دوجملهای و پوآسون کمیت مشابهی را توصیف میکنند، بنابراین خواص مشابهی
دارند : (شکل 3-4
):
هردو توزیع در اطراف k یک نقطه بیشینه دارند. اگر p را افزایش دهیم، شبکه
چگالتر میشود و باعث افزایش < k > افزایشیافته شده و نقطه بیشینه به سمت
راست حرکت میکند.
کشیدگی توزیع (پراکندگی ) نیز توسط < k > یا p کنترل میشود. هرچه شبکه
چگالتر باشد، توزیع کشیدهتر است، بنابراین تفاوت بین درجههایی که توزیع
میسازد هم بیشتر خواهد بود.
وقتی از فرم پوآسون (رابطه 3-8) استفاده میکنیم باید این را در ذهن داشته باشیم
که:
توزیع درجه دقیقا با مدل توزیع دوجملهای تطبیق دارد (رابطه 3-7)، و رابطه
(3-8) تنها تخمینی از رابطه (3-7) را به دستارائه میدهد که در محدوده ≪N
معتبر است.
مزیت فرم پوآسون این است که ویژگیهای کلیدی شبکه مثل < k >، <k2>
و σk، شکل بسیار سادهتری دارند (شکل
3-4) و به یک پارامتر وابسته هستند.
توزیع پوآسون در رابطه (3-8) صراحتاً به تعداد گرهها یا N بستگی ندارد.
بنابراین رابطه (3-8) توزیع درجه شبکههایی با اندازههای مختلف را پیشبینی
میکند ولی متوسط درجه گرهها < k > از یکدیگر قابلتشخیص نیستند (شکل
3-5).
بهطور خلاصه، اگرچه توزیع پوآسون تنها تخمینی از توزیع درجه یک شبکه تصادفی
است، ولی ازنظر تحلیلی ساده است و برای pk ترجیح دارد.
بنابراین در خلال این کتاب، بهجز جایی که ذکر شود، ما از فرم پوآسون (رابطه 3-8)
بهعنوان توزیع درجه شبکه تصادفی استفاده میکنیم. ویژگی کلیدی آن فرم پوآسون این
است که مشخصههای آن مستقل از اندازه شبکه است و تنها به یک پارامتر درجه متوسط یا
< k > وابسته است.
شکل 3-5 توزیع درجه از اندازه شبکه مستقل است
توزیع درجه یک شبکه تصادفی با k >=50> و N = 102, 103,
104 .
شبکههای کوچک: دوجملهای
برای یک شبکه کوچک (N = 102) توزیع درجه بهطور قابلملاحظهای
با فرم پوآسون متفاوت میشود است (3-8)، زیرا شرط تخمین پوآسون، یعنی < N >> < k ،
برآورده نشده است. بنابراین برای شبکههای کوچک لازم است از فرم دقیق دوجملهای
استفاده شود (3-7) (خط سبز).
شبکههای بزرگ: پوآسون
برای شبکههای بزرگ (N = 103, 104) توزیع درجه و
پیشبینی پوآسون (3-8) نزدیک به هم هستند، که با خط پیوسته خاکستری نشان داده شده
است. بنابراین برای N بزرگ توزیع درجه مستقل از اندازه شبکه است. این شکل بر اساس
میانگین اطلاعات 1000 شبکه تصادفی مستقل تولید شده تا نویز کاهش یابد.
بخش 3-5
شبکههای واقعی، پوآسون نیستند
ازآنجاکه درجه یک گره در شبکه تصادفی میتواند بین 0 و N-1 متغیر باشد، این سؤال
پیش میآید که تفاوت بین درجات گرهها در تحقق مشخصی از یک شبکه تصادفی معین چقدر
بزرگ است؟ یعنی آیا امکان دارد گرههایی با درجه بزرگ در کنار گرههایی با درجه
کوچک وجود داشته باشد؟ برای پرداختن به این سؤال، اندازه بزرگترین و کوچکترین گره
در یک شبکه تصادفی را برآورد میکنیم.
فرض کنیم که شبکه روابط افراد در جامعه در کل دنیا، به کمک یک مدل شبکه تصادفی
توصیف شده باشد. برخلاف آنچه در ابتدا به نظر میرسد، این فرض چندان عجیب نخواهد
بود: اینکه ما چه کسی را ملاقات کنیم یا با چه کسی آشنا شده باشیم تا حد زیادی
تصادفی است.
جامعهشناسان حدس میزنند که یک فرد نوعی میتواند تا 1000 نفر را به نام
بشناسد، بر همین مبنا ما k را 1000 در نظر میگیریم. با استفاده از نتایجی که قبلاً
درباره شبکههای تصادفی به دست آوردیم، به نتایج جالبی در مورد یک جامعه تصادفی با
اندازه N ≃ 7 x 109 میرسیم (مباحث پیشرفته 3-B):
انتظار میرود فردی که در یک جامعه تصادفی دارای بیشترین ارتباطات است (گره
با بیشترین درجه)، با kmax = 1,185 نفر آشنا باشد.
درجه فردی با کمترین پیوندها برابر kmin = 816 باشد که
خیلی با < k > یا kmax متفاوت نیست.
پراکندگی یک شبکه تصادفی برابر است با σk = < k
>1/2 ، که برای k >=1000> برابر با σk=31.62
است. این یعنی تعداد دوستانی که یک فرد دارد چیزی در محدوده k > ± σk>
یا بین 968 و 1032 است، یک پنجره نسبتاً محدود..
درمجموع، در یک جامعه تصادفی انتظار میرود تعداد دوستان همه افراد کم و بیش
نزدیک به هم باشد. بنابراین اگر مردم بهصورت تصادفی به یکدیگر پیوند بخورند، ما
موارد استثنا نخواهیم داشت: نباید شاهد افرادی باشیم که خیلی اجتماعی نباشند یا
برعکس، دوستان بسیار زیادی داشته باشند. این نتیجهگیری حیرتانگیز نتیجه یک مشخصه
مهم شبکه تصادفی است: در یک شبکه تصادفی بزرگ درجه بیشتر گرهها در نزدیکی حدود < k
> است ( نکته 3-4).
این پیشبینی آشکارا با واقعیت در تناقض است. شواهد گستردهای وجود دارد از
تعداد زیاد افرادی که با بیش از 1185 نفر آشنا هستند. برای مثال در دفتر ملاقات
رئیسجمهور آمریکا، فرانکلین روزولت، حدود 22000 نام وجود دارد که با او ملاقات
شخصی داشتهاند [16, 17]. بهطور مشابه، با بررسی شبکه اجتماعی فیسبوک مشخص میشود
تعداد زیادی از افراد بیش از 5000 دوست در این شبکه ثبت کردهاند، که حداکثر تعدادی
است که در شبکه مذکور مجاز است [18]. برای فهمیدن منشأ این اختلاف، باید توزیع درجه
یک شبکه واقعی را با شبکه تصادفی مقایسه کنیم.
شکل 3-6 توزیع درجه شبکههای واقعی
توزیع درجه را برای (a) شبکه اینترنت، (b) شبکه همکاریهای علمی و (c) شبکه
برهمکنش پروتئینی (جدول
2.1) نشان میدهد. خط سبز مطابق با پیشبینی پوآسون است که با اندازهگیری < k
> برای شبکه واقعی و سپس ترسیم رابطه (3-8) بهدستآمده است. انحراف قابلملاحظه
بین دادههای واقعی و نتایج توزیع پوآسون مشخص میکند که مدل تصادفی شبکه اندازه و
بسامد گرههای با درجه بالا را کمتر از مقدار واقعی میبیند، برای گرههای با درجه
پایین نیز همین اتفاق رخ میدهد. در مقابل، مدل تصادفی شبکه در مقایسه با مدل واقعی
تعداد بیشتری از گرهها را در مجاورت < k > تخمین میزند.
بخش 3-6
تکامل یک شبکه تصادفی
مهمانی عصرانه که در ابتدای فصل به آن پرداختیم، یک روند پویا را نشان میدهد که
از N گره جدا شروع میشود، و پیوندها بهتدریج در اثر برخورد و آشنایی مهمانان با
هم اضافه میشوند. در این فرایند p به تدریج افزایش مییابد که آثار قابلتوجهی در
توپولوژی شبکه به دنبال دارد (منبع
آنلاین 3-2). برای کمیسازی این پروسه، ابتدا بررسی میکنیم که چگونه اندازه
بزرگترین خوشه متصل شبکه، NG، بر اساس < k > چگونه تغییر
میکند. دوحالت کلی را میتوان بهراحتی فهمید:
برای p=0، داریم k >=0>، پس تمام گرهها ایزوله هستند. بنابراین بزرگترین
مولفهقطعه اندازه NG = 1 دارد و برای N های بزرگ خواهیم
داشت: NG/N→0.
برای p=1 داریم k >=N-1>، بنابراین شبکه یک گراف کامل است و همه گرهها به
یک مولفهقطعه واحد تعلق دارند. بنابراین NG = N و
NG/N = 1
منبع آنلاین 3-2 تکامل یک گراف تصادفی
این ویدئو تغییر در ساختار یک شبکه تصادفی را که با افزایش p اتفاق میافتد، نمایش
نشان میدهد که با افزایش p اتفاق میافتد. این موضوع بهوضوح نشانگر عدم وجود یک
قطعه مولفه غولپیکر برای p کوچک و ظهور ناگهانی آن پس از رسیدن p به یک مقدار
آستانهای است.
میتوان انتظار داشت که اگر < k > از 0 تا N-1 افزایش یابد، بزرگترین مولفه
قطعه تدریجاً از NG = 1 تا NG = N
رشد میکند اگر < k > از 0 تا N-1 افزایش یابد. بااینحال، همانطور که
شکل 3-7a مشخص شده،
این همان حالت شرایط مورد انتظار نیست که: باقیمانده NG/N
برای همه < k > های کوچک 0 باشدصفر باقی میماند، که نشاندهنده عدم وجود یک خوشه
بزرگ است. بهمحض اینکه < k > از یک مقدار مشخص بیشتر شود، NG/N
افزایش مییابد، که علامتی است بر ظهور سریع یک خوشه بزرگ که میتوانیم آنرا
قطعه مولفه غولپیکر بنامیم. اردوش و رنی در مقاله قدیمی خود در سال 1959
پیشبینی کرده بودند شرایط ظهور قطعه غولپیکر این است که:
بهبیاندیگر ما یک مولفه غولپیکر داریم اگر و تنها اگر هر گره بهطور متوسط
بیش از یک پیوند داشته باشد (مباحث پیشرفته 3-C).
این واقعیت که برای مشاهده یک قطعه غولپیکر باید به ازای هر گره حداقل یک پیوند
داشته باشیم، دور از انتظار نیست. درواقع، برای وجود یک قطعه غولپیکر، هرکدام از
گرههایش باید به حداقل یک گره دیگر پیوند خورده باشند. این موضوع قدری غیر معمول
به نظر میرسد، بااینحال، همین یک پیوند برای پیدایش آن کافی است.
میتوانیم رابطه (3-10) را براساس p با استفاده از (3-3) بیان کنیم:
بنابراین هرچقدر شبکه بزرگتر باشد، p کوچکتری برای قطعه غولپیکر کافی است.
ظهور قطعه غولپیکر تنها یکی از تحولاتی است که با تغییر < k > مشخصه شبکه
تصادفی را بیان میکند. ما میتوانیم 4 نظام مشخص ازنظر توپولوژیک را با مشخصه
منحصر بهفردشان از هم تمییز دهیم (Image
3.7a)، هرکدامشان را با مشخصه یکتایشان:
نظام زیر بحرانی: 0 < < k > < 1 (p < 1/N
, شکل 3-7b).
برای k >=0> شبکه شامل N گره منفرد است. افزایش K یعنی داریم به تعداد N< k >
=PN(N-1)/2 پیوند به شبکه اضافه میکنیم. هنوز با k > < 1> ، ما تنهاهمچنان تعداد
کمی پیوند در این نظام داریم، بنابراین عمدتاً خوشههای کوچکی را مشاهده میکنیم (شکل
3-7b).
میتوانیم در هرلحظه بزرگترین قطعه را بهعنوان قطعه
غولپیکر تعیین کنیم. هنوز، در این نظام اندازه نسبی بزرگترین خوشه NG/N
صفر میماند. علت آن است که زیر برای < k ><1 بزرگترین خوشه، درختی است با اندازه
NG ~ lnN ، بنابراین اندازه آن با سرعتی بسیار کمتر
از اندازه شبکه افزایش مییابد. بنابراین برای حالت حدی N→∞ داریم NG/N
≈ lnN/N .
بهطور خلاصه، شبکه در نظام زیر بحرانی شامل تعدادی قطعه کوچک است، که
اندازهشان از یک توزیع نمایی پیروی میکند (3-35). بنابراین، این قطعات اندازههای
نزدیک به هم دارند و نمیتوان یکی از آنها را به عنوان برنده یا مولفه غولپیکر
انتخاب کرد.
نقطه بحرانی جداکننده، نظامی است که هنوز یک قطعه مولفه غولپیکر نیست ( k ><1>)
و نظامی که در آن یک قطعه غولپیکر وجود دارد ( k > >1>) را از هم جدا میکند. در
این نقطه اندازه نسبی بزرگترین قطعه همچنان صفر است (شکل
3-7c). درواقع، اندازه بزرگترین قطعه برابر است با NG ~
N2/3 .متعاقباً NG بسیار کندتر از اندازه
شبکه رشد میکند، بنابراین اندازه نسبی آن در حالت حدی که N→∞ به NG/N
~ N-1/3) کاهش مییابد.
در نظر داشته باشید، بااینحال، در شرایط مطلق یک پرش قابلملاحظه در اندازه
بزرگترین قطعه در < k >=1 وجود دارد. برای مثال، برای یک شبکه تصادفی با اندازه
N = 7 ×109 گره، که قابلمقایسه با شبکه اجتماعی جهانی است،
برای k ><1> بزرگترین خوشه از درجه NG ≃ lnN = ln (7
× 109) ≃ 22.7 است. در مقابل در < k >=1 ما انتظار داریم که
NG ~ N2/3 = (7 ×109)2/3
≃ 3 × 106 ، که جهشی در حدود پنج برابر بزرگترپرشی از حدود 5 مرتبه
بزرگتر است. بااینحال، در نظام زیربحرانی و در نقطه بحرانی بزرگترین قطعه مولفه،
تنها شامل بخش بسیار کوچکی از کل گرههای شبکه استرا شامل. میشود.
بهطور خلاصه، در نقطه بحرانی اکثر گرهها در چندین قطعه کوچک که توزیع
اندازهشان از رابطه (3-36) تبعیت میکند، جای میگیرند. فرم قانون-توان نشان
میدهد مولفههایی با اندازههای متفاوت همزمان باهم وجود دارند. این قطعات کوچک
عمدتاً درخت هستند، درحالیکه قطعه غولپیکر ممکن است شامل حلقههایی باشد. در نظر
داشته باشید که بسیاری از مشخصات شبکه در نقطه بحرانی شبیه به یک سیستم فیزیکی است
که در حال تغییر فاز است (مباحث پیشرفته 3-F).
شکل 3-7 تکامل یک شبکه تصادفی
اندازه نسبی قطعه غولپیکر بهصورت تابعی از میانگین درجه < k > در مدل
اردوش-رنی. تصویر نمایانگر تغییر فاز در < k >=1 است که عامل ظهور یک قطعه
غولپیکر با NG غیر صفر است.
یک شبکه نمونه و ویژگیهای آن در چهار نظام که مشخصات شبکه تصادفی را نشان
میدهد.
این نظام بیشترین شباهت را با سیستمهای واقعی دارد، برای اولین بار ما یک قطعه
غولپیکر داریم که شبیه به یک شبکه است. در مجاورت نقطه بحرانی اندازه قطعه
غولپیکر متغیر است همچنان که:
یا
که pc در رابطه (3-11) داده شده است. بهبیاندیگر قطعه
غولپیکر شامل بخش محدودی از گرهها است. وقتی از نقطه بحرانی فراتر برویم، بخش
بزرگتری از گرهها به آن تعلق خواهند داشت. در نظر داشته باشید که رابطه (3-12)
تنها در مجاورت < k >=1 معتبر است. برای < k > های بزرگ وابستگی بین NG
و < k > غیرخطی است .(Image
3.7a).
بهطور خلاصه در نظام فرا بحرانی تعدادی قطعه کوچک در کنار قطعه غولپیکر
موجودند، که توزیع اندازه آنها از رابطه (3-35) پیروی میکند. این قطعات کوچک
درختها هستند، درحالیکه قطعات بزرگ حلقهها یا دورها هستند. تا زمانی که تمام
گرهها جذب قطعه غولپیکر شوند، نظام فرا بحرانی برپاست.
برای p بهاندازه کافی بزرگ، قطعه غولپیکر همه گرهها و قطعات دیگر را جذب
میکند، بنابراین NG= N است. در غیاب گرههای منفرد
شبکه ، به شبکه متصل تبدیل میشودبه طور کامل پیوند میخورد. درجه میانگین برای رخ
دادن این حالت به N بستگی دارد زیرا (مباحث پیشرفته 3-e):
در نظر داشته باشید وقتی وارد نظام متصل میشویم شبکه همچنان نسبتاً تنک است
زیرا برای N های بزرگ ln(N)/ N →0. شبکه تبدیل به یک گراف کامل میشود تنها
وقتیکه < k >=N-1 باشد.
بهطور خلاصه، مدل تصادفی شبکه پیشبینی میکند که ظهور شبکه یک فرایند هموار و
تدریجی نیست: گرههای منفرد و قطعات کوچکی که برای بهازای مقدار کوچک کوچک
مشاهده شدند در خلال یک تغییر فاز ازبین رفته و به داخل یک قطعه مولفه غولپیکر
تبدیل میشوندفروپاشی میکنند (مباحث پیشرفته 3-f). همچنان که را تغییر میدهیم
با 4 نظام منحصربهفرد ازنظر توپولوژیکی مواجه میشویم (Image
3.7).
بحثی که در بالا به آن پرداختیم با مشاهدات تجربی نیز تطبیق دارد و زمانی که
میخواهیم یک شبکه تصادفی را با سیستم واقعی مقایسه کنیم مثمر ثمر خواهد بود. یک
زاویه دید متفاوت و مشی ارزشمند در (نکته 3-5) با ادبیات ریاضی معرفی شده است.
بخش 3-7
شبکههای واقعی فرا بحرانی هستند
دو پیشبینی از نظریه شبکههای تصادفی مستقیما برای شبکههای واقعی مهم هستند:
لحظهای که درجه میانگین از < k > = 1 فراتر رود، قطعه غولپیکری باید ظاهر
شود که شامل بخش محدودی از کل گرهها باشد. بنابراین تنها برای < k > > 1
گرهها خود را به شکل یک شبکه، سازماندهی میکنند.
برای < k > > ln(N) تمام قطعات توسط قطعه غولپیکر جذبشدهاند، که به یک
شبکه واحد متصل منتج میشود.
آیا شبکههای واقعی شرط وجود قطعه غولپیکر را برآورده میکنند، یعنی < k > > 1
؟ و آیا این قطعه غولپیکر تمام گرهها را به ازای < k > > ln(N) شامل میشود یا
اینکه ما هنوز میتوانیم قطعات غیر متصلی را پیدا کنیم؟ برای پاسخ دادن به این سؤال
ما ساختار یک شبکه واقعی را با پیشبینیهای نظری که در بالا بحث شد مقایسه
میکنیم.
اندازهگیریها نشان میدهند که شبکههای واقعی از آستانه < k > = 1 بهشدت
فراتر میروند. جامعهشناسان تخمین میزنند که یک فرد بهطور متوسط بیش از1000 آشنا
دارد؛ یک نورون خاص در مغز انسان حدود 7000 سیناپس دارد؛ در سلولهای ما هر مولکول
در چندین واکنش شیمیایی شرکت میکند.
جدول 3-1 که درجه میانگین چندین شبکه غیر جهت دار را ارائه کرده است هم این
مقایسه را تایید میکند. در هر حالت میبینیم < k > > 1 است. بنابراین درجه میانگین
شبکههای واقعی بهدرستی، زیر آستانه < k > = 1 قراردارد که نشان میدهد آنها یک
مولفه غولپیکر دارند. موردی مشابه برای شبکههای مرجعی که در
جدول 3-1 ارائه شدهاند،
برقرار است.
شبکه
N
L
< K >
lnN
اینترنت
192,244
609,066
6.34
12.17
شبکه برق
4,941
6,594
2.67
8.51
همکاری علمی
23,133
94,437
8.08
10.05
شبکه بازیگران
702,388
29,397,908
83.71
13.46
برهمکنش پروتئینی
2,018
2,930
2.90
7.61
جدول 3-1 آیا شبکههای واقعی متصل هستند؟
تعداد گرهها N و تعداد پیوندها L برای شبکههای غیر جهتدار برای لیست شبکههای
ارجاعی مرجع شبکههای جدول
3-1، با هم بهصورت < k > و ln(N) نمایش دادهشدهاند. برای < k >>1یک قطعه
غولپیکر برای < k >>1 مورد انتظار است و برای بهازای < k >>ln(N) همه گرهها
باید به قطعه غولپیکر ملحق شوند. بااینکه برای همه شبکهها < k >>1 است، برای
بیشتر آنها < k > کمتر از آستانه ln(N) است (شکل
3-9 را هم ببینید).
حال اجازه دهید به پیشبینی دوم برگردیم، و حالاتی که اگر ما یک قطعه داشته
باشیم (یعنی < k > > ln(N))، یا اگر شبکه به چندین قطعه تجزیه شده باشد (یعنی اگر
< k > < ln(N) باشد) را بررسی کنیم. برای شبکههای اجتماعی گذار بین نظام فرا
بحرانی و نظام تمام متصل، باید مقدار < k> > ln(7*109) ≈
22.7 باشد. یعنی اگر یک فرد میانگین بیش از دو دوجین آشنا داشته باشد، آنگاه
جامعه تصادفی باید یک قطعه مولفه واحد داشته باشد که هیچ فردی را غیر متصل
نگذارد. با < k >≈1000 چنین شرطی بهوضوح برآورده شده است. بااینوجود، طبق
جدول 3-1 بسیاری از
شبکههای واقعی از شرط پیوند قوی پیروی نمیکنند. بر اساس نظریه شبکههای تصادفی،
این شبکهها باید به چندین زیرشبکه مجزا افراز شوند. این پیشبینی در مورد
شبکهای مانند اینترنت ناامید کننده است، زیرا بیان میکند باید مسیریابهایی
وجود داشته باشند که به مولفه غولپیکر متصل نبوده و نتوانند با دیگر مسیریابها
در ارتباط باشند به این معنی است که زیرشبکههایی باید وجود داشته باشد که
نتوانند با مسیریابهای دیگر متصل شوند و در نتیجه زیرشبکههای ایزوله و مجزا
تشکیل شود. در مورد شبکه انتقال برق هم همین مسئله صادق است و طبق این پیشبینی
باید مجموعهای از مشترکین وجود داشته باشند که نمیتوانند به شبکه متصل شده و از
انرژی برق استفاده کنند. بدیهی است این نتایج فاصله زیادی با واقعیت دارد.
بهطور خلاصه، تا کنون دریافتیم که اکثر شبکههای واقعی در نظام فرا بحرانی قرار
دارند (شکل
3-9). بنابراین انتظار میرود این شبکهها یک قطعه غولپیکر داشته باشند که با
مشاهدات واقعی منطبق است. بااینحال، در کنار این قطعه غولپیکر باید تعداد زیادی
قطعه غیرهمبند وجود داشته باشد، که این پیشبینی برای چندین شبکه واقعی درست از آب
درنمیآید. در نظر داشته باشید که این پیشبینیها تنها زمانی معتبر هستند که
شبکههای واقعی دقیقاً با مدل اردوش-رنی منطبق باشند و ماهیت تصادفی داشته باشند.
در بخش پیش رو، بیشتر با ساختار شبکههای واقعی آشنا خواهیم شد و خواهیم فهمید چرا
شبکههای واقعی میتوانند علیرغم برآورده نشدن شرط k > ln(N) متصل بمانند.
شکل 3-9 بیشتر شبکههای واقعی فرا بحرانی هستند.
چهار نظام پیشبینیشده توسط نظریه تصادفی شبکه را نشان میدهد که محل < k > برای
شبکههای غیر جهتدار مذکور در
جدول 3-1 با علامت ضربدر مشخصشده است. این تصویر مشخص میکند که بیشتر
شبکههای واقعی در نظام فرا بحرانی قرار دارند، بنابراین انتظار میرود آنها به
تعدادی زیرشبکه کوچک تجزیه شوند، فقط شبکه هنرمندان در نظام متصل قرار میگیرد که
بدان معناست که همه گرهها بخشی از یک قطعه غولپیکر واحد هستند. در نظر داشته
باشید مرز بین نظام زیربحرانی و فرا بحرانی همیشه در < k >=1 و برای همه سیستمها
یکسان است، اما مرز بین نظام فرا بحرانی و متصل در ln(N) قرار دارد، که از سیستمی
به سیستم دیگر فرق دارد.
بخش 3-8
جهانهای کوچک
پدیده جهان کوچک، که بهعنوان فاصله با شش واسطه نیز شناخته میشود، مدتهاست که
در بین عموم مردم شناخته شده است. این پدیده بیان میکند که بین هر دو فرد دلخواه
میتوان مسیری با حداکثر 6 واسطه از آشنایان پیدا کرد، به عبارتی هر دو نفر با شش
واسطه یکدیگر را میشناسند (شکل
3-10). این موضوع برای مردمی که در یک شهر زندگی میکنند، اصلا عجیب نیست، اما
مفهوم دنیای کوچک حتی برای افرادی که در دو سوی مختلف جهان هستند نیز صادق است.
شکل 3-10 شش گام فاصله
در پدیده شش گام فاصله ، دو فرد در هرکجای جهان میتوانند از طریق زنجیرهای از
آشنایان با طول 6 یا کمتر به هم متصل شوند. این بدان معنی است که اگرچه سارا
مستقیما پیتر را نمیشناسد، اما رالف را میشناسد که او جان را میشناسد که درنهایت
او پیتر را میشناسد. پس سارا 3 گام با پیتر فاصله دارد یا در درجه سوم از پیتر
است. مفهوم فاصله شش درجه که به آن ویژگی جهان کوچک هم گفته میشود، در ادبیات علم
شبکه بدان معنی است که فاصله بین هر دو گره در یک شبکه بهطور غیرمنتظرهای کوچک
است..
به زبان علم شبکه، پدیده جهان کوچک بیان میکند که فاصله بین هر دو گره دلخواه
(تصادفی) در شبکه کوتاه است. لازم است به دو سؤال پاسخ داده شود: معیار کوتاه
بودن فاصله چیست و در مقایسه با چه چیزی سنجیده میشود؟ چطور میتوان وجود این
فواصل کوتاه را توضیح داد؟
هردو سؤال با محاسبه سادهای پاسخ داده میشوند. یک شبکه تصادفی با درجه میانگین
را در نظر بگیرید. یک گره در این شبکه بهطور میانگین دارای:
< k > گره در فاصله (d=1).
‹k›2گره در فاصله ،(d=2).
‹k›3 گره در فاصله ،(d =3).
...
‹k›d گره در فاصله d.
است. برای مثال، هر فرد به طور متوسط با 1000 نفر آشنا است، پس اگر < k >≈1000
در نظر بگیریم، انتظار داریم 106 فرد در فاصله 2 از یکدیگر باشند و در
حدود یک میلیارد نفر، یعنی تقریباً تمام جمعیت زمین، در فاصله 3 از ما قرار داشته
باشند.
به بیانی دقیقتر، تعداد گرههای مورد انتظار با فاصله d از یک گره برابر است
با:
N(d) نباید از تعداد کل گرهها در شبکه، N، فراتر رود. بنابراین فواصل
نمیتوانند هر مقدار دلخواهی بگیرند. ما میتوانیم بیشترین فاصله، dmax،
یا قطر شبکه را با مقدار
مشخص کنیم. با فرض اینکه < k > > 1، میتوانیم (-1) را در صورت و مخرج رابطه
(3-15) نادیده بگیریم که خواهیم داشت:
بنابراین قطر یک شبکه تصادفی از عبارت زیر پیروی میکند:
که بیانگر فرمولبندی ریاضی پدیده جهان کوچک است. اگرچه نکته مهم، در تفسیر آن
است:
رابطه (3-18) مقیاس بندی قطر شبکه، dmax، را برای
سیستمی با اندازه N محاسبه میکند. برای بیشتر شبکهها (3-18) تخمین بهتری از
فاصله میانگین بین دو گرهای که بطور تصادفی انتخاب شدهاند نسبت به dmax
پیشنهاد میکند (جدول
3-2). این بدان خاطر است که dmax معمولاً به واسطه
تعداد کمی مسیر تعریف میشود، درحالیکه میانگین بین همه جفت مسیرها است،
این فرایند باعث از بین رفتن اختلاف زیاد در تخمین ها می شود ازاینرو معمولاً
مشخصه دنیای کوچک اینگونه تعریف میشود:
که نیازمندی های میانگین فاصله در شبکه ای با پارامترهای N و ر را توصیف
می کند.
بهطورکلی ln(N)≪N است، بنابراین وابستگی < d > به ln(N) نشاندهنده آن
است که فواصل در یک شبکه تصادفی نسبت بهاندازه شبکه بسیار کوچکتر هستند.
درنتیجه منظورمان از کوچک (کوتاه) در پدیده جهان کوچک این است که طول مسیر
میانگین یا قطر بهصورت لگاریتمی بهاندازه سیستم وابسته است. بنابراین "کوچک"
یعنی با ln(N) متناسب است، نه با N یا توانی از N (شکل
3-11).
عبارت 1/ln< k > دلالت دارد بر اینکه هرچقدر شبکه متراکمتر باشد، فاصله
بین گرهها کوتاهتر است.
• در شبکههای واقعی رابطه (3-19) اصلاح میشود و این واقعیت آشکار میشود
که تعداد گرهها در فاصله d > بهسرعت کم میشود (مباحث پیشرفته 3-f).
شکل 3-11 چرا پدیده جهان کوچک غیرمنتظره است؟
بخش اعظم شهود ما درباره فاصله بر تجربه ما از توریهای منظم استوار است، که
ویژگی جهان کوچک را نشان نمیدهد:
توری یکبعدی: برای یک توری منظم یکبعدی (خطی به طول N) قطر و
میانگین طول مسیر بر اساس N بهصورت خطی رشد میکند: dmax~‹d›
~N
توری دوبعدی: برای توری منظم مربعی dmax~‹d›
~ N1/2 است.
توری سهبعدی: برای توری منظم مکعبی dmax~‹d›
~ N1/3است.
چهاربعدی: بهطورکلی، برای توری منظم d-بعدی dmax~‹d›
~ N1/d است.
این وابستگیهای نماییچندجانبه افزایش سریعتری برای N نسبت به رابطه (3-19)
قائلاند، که مشخص میکند در توریهای منظم طول مسیرها بهطور قابلملاحظهای
طولانیتر از شبکه تصادفی است. برای مثال اگر شبکههای اجتماعی یک توری منظم مربعی
(2-بعدی) تشکیل میداد، که در آن هر شخص تنها همسایگانش را میشناخت، فاصله میانگین
بین دو فرد دقیقاً (7 ×109)1/2 = 83,666 میشد. حتی اگر این
واقعیت را هم اصلاح کنیم که هر شخص حدود 1000 آشنا دارد، نه چهارتا، بازهم متوسط
جدایی از مرتبهای بزرگتر ازآنچه توسط رابطه (3-19) پیشبینیشده است، به دست
میآمد.
شکل N-وابستگی پیشبینیشده < d > برای شبکههای منظم و تصادفی در یک مقیاس
خطی را پیشبینی میکند.
همانند (a)، ولی در مقیاس لگاریتم نمایش داده شده است
اجازه دهید پیامدهای رابطه 3-19 را برای شبکههای اجتماعی توضیح دهیم. با در
نظر گرفتن N ≈ 7 ×109 and ‹k› ≈ 103 ،
خواهیم داشت:
بنابرین همه افراد روی زمین باید در فاصله آشنایی 3 یا 4 از یکدیگر قرار داشته
باشند [20]. تخمین رابطه (3-20) احتمالاً به مقدار واقعی نزدیک تراست تا درجه 6،
که بیشتر نقل میشود (نکته 3-7).
بیشتر آن چیزی که ما از ویژگی جهان کوچک در شبکههای تصادفی میدانیم، که نتیجه
رابطه (3-19) را هم دربر میگیرد، از مقاله کوتاه و معروف به قلم مانفرد کوهن و
سولاپول [20] است. در این مقاله مسئله را بهصورت ریاضی فرمولهبندی کرده و
پیامدهای اجتماعی آنرا بهطور عمیق بررسی کردند. این مقاله الهام بخش آزمایش معروف
میلگرام (نکته 3-6) است که آن هم بهنوبه خود الهام بخش عبارت شش گام فاصله است.
بااینکه ویژگی شش گام فاصله در حوزه نظامهای اجتماعی کشف شده، ولی کاربرد آن
فراتر از شبکههای افراد در جامعه است (نکته 3-6). برای اثبات این موضوع فاصله
برآوردی از رابطه (3-19) را برای میانگین طول برای چندین شبکه واقعی مقایسه شده
و نتیجه در در
جدول 3-2 نشان داده شده است. علیرغم تنوع این سیستمها و وجود تفاوت
قابلملاحظه بین آنها ازنظر مقدار N و ، رابطه (3-19) تخمین خوبی برای که
بهطور تجربی مشاهده شده ارائه میدهد.
بهطور خلاصه، ویژگی جهان کوچک نهتنها تصورات رایج را برهم زده است (نکته
3-8)، بلکه نقش مهمی هم در علم شبکه بازی میکند. مفهوم جهان کوچک میتواند به
کمک مدلهای تصادفی شبکه بهخوبی توجیه شود: زیرا تعداد گرهها در فاصله d از یک
گره با افزایش d بهطور نمایی افزایش مییابد. در فصلهای پیش رو خواهیم دید که
شبکههای واقعی دقیقا با رابطه (3-19) منطبق نیستند و مجبور خواهیم شد مدلهای
دقیقتری را جایگزین کنیم، بااینحال، درکی که مدل شبکه تصادفی درباره منشأ پدیده
جهان کوچک در اختیار میگذارد، بسیار ارزشمند است.
شبکه
N
L
< k >
< d >
dmax
lnN/ln< k>
اینترنت
192,244
609,066
6.34
6.98
26
6.58
وب
325,729
1,497,134
4.60
11.27
93
8.31
شبکه برق
4,941
6,594
2.67
18.99
46
8.66
تماس های تلفن همراه
36,595
91,826
2.51
11.72
39
11.42
پست الکترونیکی
57,194
103,731
1.81
5.88
18
18.4
همکاری علمی
23,133
93,437
8.08
5.35
15
4.81
شبکه بازیگران
702,388
29,397,908
83.71
3.91
14
3.04
شبکه ارجاعات علمی
449,673
4,707,958
10.43
11.21
42
5.55
E. Coli متابولیسم
1,039
5,802
5.58
2.98
8
4.04
شبکه برهمکنش پروتئینی
2,018
2,930
2.90
5.61
14
7.14
جدول 3-2 6 گام فاصله
فاصله میانگین ‹d› و فاصله بیشینه dmax برای 10 شبکه
مرجع را نشان میدهد. ستون آخر مقدار برآوردی را از طریق رابطه (3-19) نشان
میدهد، که تخمین نسبتا منطقی از معیار است، هر چند هنوز به طور کامل با آن
تطبیق ندارد، در فصلهای بعد مشاهده خواهیم کرد که برای بسیاری از شبکههای واقعی
نیاز است رابطه (3-19) اصلاح شود. برای شبکههای جهتدار، درجه میانگین و طول
مسیرها بر اساس جهت پیوندها اندازهگیری میشود.
بخش 3-9
ضرایب خوشهبندی
درجهیک گره هیچ اطلاعاتی درباره همسایههای آن گره نمیدهد، آیا آنها هم
یکدیگر را میشناسند یا اینکه از هم ایزوله هستند؟ پاسخ با ضریب خوشهبندی محلی
Ci، که چگالی پیوندها را در همسایگی مستقیم گره i محاسبه میکند
مرتبط است: Ci=0 یعنی هیچ پیوندی بین همسایههای i وجود ندارد؛
Ci=1 نشان میدهد هرکدام از همسایگان i به هم وصل هستند (بخش
2.10).
جهت در محاسبه Ci برای گرهای در شبکه تصادفی، باید میزان
پیوندهای مورد انتظارLi بین ki همسایه گره
را تخمین بزنیم. در شبکه تصادفی احتمال پیوند دو همسایه از گره i برابر p است.
ازآنجاکه به تعداد ki(ki - 1)/2پیوند ممکن
بین ki همسایه گره i وجود دارد، تعداد پیوندهای مورد انتظار
Li برابر است با:
بنابراین ضریب خوشهبندی محلی برای یک شبکه تصادفی برابر است با :
رابطه (3-21) دو نتیجه در پی دارد:
برای مقدار ثابت ، هرچقدر شبکه بزرگتر باشد، ضریب خوشهبندی گرهها
کوچکتر است. متعاقباً انتظار میرود ضریب خوشهبندی محلی Ci
گره i نیز متناسب با 1/N کاهش یابد. در نظر داشته باشید که رفتار ضریب
خوشهبندی میانگین شبکه یا نیز به همین ترتیب است (3-21).
2. ضریب خوشهبندی محلی یک گره مستقل از درجه گره است.
جهت بررسی اعتبار صحت رابطه (3-21) نمودار ‹C›/‹k› را برحسب N
برای چندین شبکه غیر جهتدار ترسیم میکنیم (شکل
3-13a). نمودارها نشان میدهند که ‹C›/‹k› همراه با N-1
کاهش نمییابد، و نسبتا مستقل از N به نظر میرسد که با رابطه (3-21) در تناقض است.
همچنین در شکلهای
3-13
(ب-د) استقلال C از درجه گره ki برای سه شبکه واقعی نمایش
داده شده است. این شکل ها نشان می دهند که C با افزایش درجه کاهش مییابد، که
مجدداً با معادله (3-21) و نکته (2) در بالا در تناقض است.
بهطور خلاصه، دریافتیم که مدل تصادفی شبکه، خوشهبندی شبکههای واقعی را
بازنمایی نمیکند. در مقابل، شبکههای واقعی ضریب خوشهبندی بسیار بالاتری نسبت به
شبکه تصادفی با پارامترهای N و L مشابه دارند. مدل تصادفی شبکه توسط واتز و
استروگاتز توسعه داده شد [20] تا بتواند همزمان پدیده جهان کوچک و مقدار بالای C
را توجیه کند (جعبه نکته 3-9). این مدل در تفسیر نتایج موفق نبود ولی توانست توضیح
دهد که چرا گرههای با درجه بالا ضریب خوشهبندی کوچکتری نسبت به گرههای با درجه
کمتر دارند. مدلهایی که شکل C(K) را توضیح میدهند در فصل 9 توضیح داده شدهاند.
شکل 3-13 خوشه بندی در شبکه های واقعی
مقایسه ضریب خوشهبندی متوسط شبکههای واقعی با پیشبینی رابطه (3-21) برای
شبکههای تصادفی را نشان میدهد. دایرهها و رنگ آنها با شبکههای
جدول 3-2 مطابقت دارد. شبکههای جهتدار برای محاسبه < C > و < k > بهصورت
غیر جهتدار ساخته شدند. خط سبز که مربوط به رابطه (3-21) است، پیشبینی میکند
برای شبکههای تصادفی، متوسط ضریب خوشهبندی به N-1N-1
کاهش مییابد. در مقابل، برای شبکههای واقعی مستقل از N به نظر میرسد.
وابستگی ضریب خوشهبندی محلی، C(k)، را به درجه گره برای شبکههای (ب)
اینترنت ، (ج) شبکه همکاری علمی و (د) شبکه برهمکنش پروتئینی نشان میدهد.
C(k) با میانگینگیری از ضریب خوشهبندی محلی همه گرهها با درجه k اندازهگیری
شده است. خط افقی سبز را نشان می¬دهد.
بخش 3-10
خلاصه: شبکههای واقعی تصادفی نیستند
از زمان معرفی مدل تصادفی شبکه در سال 1959 این مدل بر رویکردهای ریاضی شبکههای
پیچیده حاکم بوده است. در این مدل پیشنهاد میشود شبکههایی که در سیستمهای
پیچیده، تصادفی به نظر میرسند را باید بصورت کاملا تصادفی توصیف کرد. چنانچه مدل
شبکه های تصادفی را برای سیستم های پیچیده بپذیریم، به این معنی خواهد بود که
پیچیده بودن یک سیستم را معادل تصادفی بودن آن دانستهایم. اینجاست که یک سوال
اساسی شکل میگیرد:
آیا واقعا معتقدیم شبکههای واقعی، تصادفی هستند؟
جواب بهوضوح منفی است. همانطور که یک سلول نمی تواند وظایفش را به صورت تصادفی
انجام دهد و تعامل بین پروتئینهای ما توسط قواعد دقیق بیوشیمی اداره میشود.
بهطور مشابه در یک جامعه تصادفی یک دانشآموز آمریکایی میتواند بهجای
همکلاسیهایش با یک کارگر چینی دوست شود، درحالیکه در واقعیت چنین اتفاقی رخ
نمیدهد.
در واقعیت، ما به وجود یک نظم عمیق در پس اکثر سیستمهای پیچیده واقف هستیم. آن
نظم باید در ساختار شبکهای که معماری آنها را توصیف میکند منعکسشده باشد، که
باعث میشود بصورت قاعدهمندی از تصادفی بودن محض پیکربندی فاصله بگیرد.
اینکه تا چه حد مدل شبکههای تصادفی میتواند شبکههای واقعی را توصیف کند را می
توان به کمک مشاهدات و محاسبات کمی دریافت و نیازی به استدلال های معرفتشناختی
پیچیده نیست. این مشاهدات عبارتاند از:
توزیع درجه
شبکه تصادفی یک توزیع دوجملهای دارد که میتوان آنرا بهاگر شرط k «
N برقرار باشد، آنرا با یک توزیع پوآسون بهخوبی تخمین زد. بااینحال،
همانطور که در
شکل
3-5 نشان دادهشده، توزیع پوآسون با توزیع درجه شبکههای واقعی سازگار نیست. در
سیستمهای واقعی ما گرههای با پیوندهای بیشتری نسبت به مدل تصادفی داریم.
متصل بودن
نظریه شبکه تصادفی پیشبینی میکند که برای ‹k› › 1 باید شاهد یک قطعه
غولپیکر باشیم، شرطی که در همه شبکههایی که امتحان کردیم برآورده شد. بااینحال،
بیشتر شبکهها شرط ‹k› › lnN را برآورده نمیکنند، که نشان
میدهد آنها باید به خوشههای کوچکتری شکسته شوند (جدول
3-1)، در حالی که بیشتر شبکه های واقعی کاملا یکپارچه هستند و به خوشههای کوچک
افراز نشدهاند.
میانگین طول مسیر
قضیه شبکه تصادفی پیشبینی میکند که میانگین طول مسیر (فاصله) از رابطه (3-19)
پیروی میکند. این پیش بینی تخمینی منطقی برای طول مسیرهای مشاهدهشده ارائه
میدهد. بنابراین مدل تصادفی شبکه میتواند ظهور پدیده جهان کوچک را توجیه کند.
ضریب خوشهبندی
در شبکه تصادفی ضریب خوشهبندی محلی مستقل از درجه گره است و ‹C›
بهاندازه سیستم و 1/N بستگی دارد. در مقابل، اندازهگیریها مشخص میکنند برای
شبکههای واقعی C(K) همراه با درجه گره کاهش مییابد و تا حد زیادی از اندازه سیستم
مستقل است (شکل 3-13).
درنهایت، به نظر میرسد پدیده جهان کوچک تنها ویژگیای است که توسط مدل تصادفی
شبکه بهطور منطقی قابل توضیح است. بقیه مشخصات، از توزیع درجه گرفته تا ضرایب خوشه
بندی، در شبکههای واقعی متفاوت هستند. مدل توسعهیافته اردوش-رنی که توسط واتز و
استروگاتز ارائه شد با موفقیت وجود همزمان ضرایب خوشه بندی بالا(c) و فواصل پایین
(‹d›) را پیشبینی میکند، ولی نمیتواند توزیع درجه و C(K) را توضیح دهد.
در حقیقت هرچه بیشتر درباره شبکههای واقعی میآموزیم، بیشتر به این نتیجه میرسیم
که هیچ یک از شبکههای واقعی را نمیتوانیم با مدل تصادفی شبکه به دقت توصیف کنیم.
شاید این سؤال مطرح شود که اگر شبکههای واقعی تصادفی نیستند، پس چرا ما یک فصل
کامل را به آن اختصاص دادیم؟ پاسخ ساده است: وقتی میخواهیم ویژگیهای شبکههای
واقعی را کاوش کنیم این مدل بهمانند مرجع مهمی عمل میکند. هرگاه یک ویژگی شبکه را
مشاهده میکنیم باید بپرسیم که آیا اتفاقی بوده یا نه. برای این منظور از مدل
تصادفی شبکه بهعنوان راهنما استفاده میکنیم: اگر آن ویژگی در مدل تصادفی وجود
دارد، به عبارتی مدل تصادفی قادر به توجیه آن است، آن ویژگی را تصادفی به شمار می
آوریم و در غیر اینصورت باید به دنبال نظمی عمیقتر بگردیم که بتواند ریشه آن را
توضیح دهد. پس شاید مدل تصادفی شبکه نتواند اکثر سیستمهای واقعی را توجیه کند، ولی
برای علم شبکه بسیار مفید خواهد بود (نکته 3-10).
بخش 3-11
تمرین
شبکههای اردوش-رنی
یک شبکه اردوش-رنی با N=3000 گره را در نظر بگیرید که گرهها با احتمالp
= 10–3 به هم پیوند خوردهاند.
تعداد پیوندهای مورد انتظار 〈L〉 چقدر است؟
(b) شبکه در کدام نظام قرار دارد؟
مقدار احتمال pc را برای زمانی که شبکه در نقطه
بحرانی قرار دارد حساب کنید.
با در نظر گرفتن احتمال پیوند p = 10–3، تعداد
گرهها Ncr را برای زمانی که شبکه تنها یک قطعه داشته
باشد محاسبه کنید.
برای شبکه سؤال (d)، مقدار درجه میانگین 〈kcr〉 و
فاصله میانگین بین دو گره 〈d〉 که بهطور تصادفی انتخابشده باشند
را محاسبه کنید.
توزیع درجه pk را برای این شبکه محاسبه کنید (با
یک توزیع درجه پوآسون تخمین بزنید)..
ایجاد شبکههای اردوش-رنی
با توجه به مدل G(N,p) به کمک کامپیوتر سه شبکه با N=500 گره و با درجه
میانگین به ترتیب (a) 〈k〉 = 0.8 و (b) 〈k〉 = 1 و (c) em>〈k〉
= 8 بسازید.
شبکههای دایرهای
شبکهای با N گره را در نظر بگیرید که روی یک دایره واقع شده است، بنابراین
هر گره به m همسایه در دو طرفش پیوند خورده است (پس هر گره از درجه 2m است).
شکل 3-14(a)) نمونهای از این شبکه با N=20 و m=2 را نشان میدهد. میانگین
ضریب خوشهبندی 〈C〉 و میانگین کوتاهترین مسیر 〈d〉 را برای
این شبکه حساب کنید. برای سادگی فرض کنید که N و m طوری انتخاب شدهاند که
(n-1)/2m یک عدد صحیح باشد. اگر N≫ باشد برای 〈C〉 و 〈d〉
چه اتفاقی می افتد؟
درخت کایلی
درخت Cayley کایلی یک درخت متقارن است، که با شروع از یک گره مرکزی با درجه
k ساخته میشود. هر گره در فاصله dاز گره مرکزی از با درجه k است قرار دارد تا
زمانی که به گرههایی در فاصله p میرسیم که از درجه 1 هستند و برگ نامیده
میشوند (شکل
3-16 را ببینید که یک درخت Cayley با p=5 و k=3 است.).
تعداد گرههایی که با t قدم از گره مرکزی در دسترس هستند را حساب کنید.
توزیع درجه را برای این شبکه حساب کنید.
قطر dmax درخت را حساب کنید.
رابطهای برای قطر dmax برحسب تعداد کل گرهها N
پیدا کنید.
آیا شبکه ویژگی جهان کوچک را به نمایش میگذارد؟
شبکه اسنوبیش
C
21q
بخش 3-12
مباحث پیشرفته 3-A
به دست آوردن توزیع پوآسون
برای به دست آوردن فرم پوآسون توزیع درجه، از توزیع دقیق دوجملهای که یک
گراف تصادفی را نشان میدهد، استفاده میکنیم (3-7):
که ویژگی شبکه را مشخص می کند. اولین عبارت سمت راست فرمول را بصورت زیر می
نویسیم :
اولین جزء سمت راست را بدینصورت بازنویسی میکنیم (با فرض k≪N) آخرین جزء
رابطه (3-22) میتواند بدینصورت سادهسازی شود:
و با استفاده از بسط سری زیر
فرمول زیر بدست می آید
که اگر N » kمعتبر خواهد بود. که در قلب این مشتق گیری
تخمین درحه کوچک قرار دارد. با ترکیب رابطههای (3-22)، (3-23) و (3-24)، فرم
پوآسون توزیع درجه را به دست میآوریم:
بخش 3-13
مباحث پیشرفته 3-B
بیشینه و کمینه درجه
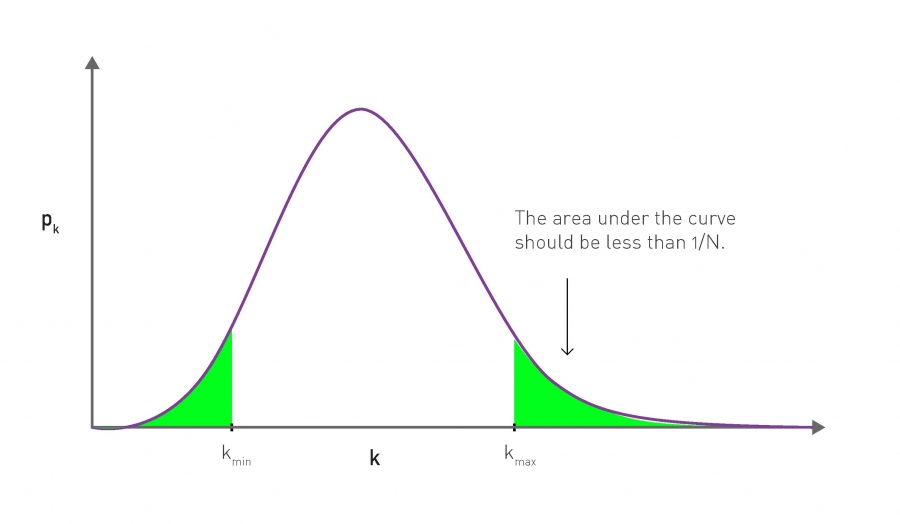
برای مشخص کردن درجه مورد انتظار بزرگترین گره در شبکه تصادفی، که برش
طبیعی فوقانی شبکه نامیده میشود، درجه kmax را
بهاینترتیب تعریف میکنیم که: در شبکهای با N گره ما حداکثر یک گره داریم که
درجهاش بیشتر ازkmax است. ازنظر ریاضی این یعنی مساحت زیر
توزیع پوآسون pk برای k ≥ kmax
باید تقریباً 1 باشد (شکل
3-17). ازآنجاکه مساحت با 1-P(kmax)) به دست
میآید، که در آن p(k) توزیع درجه تجمعی pk است، بزرگترین
گره شبکه شرایط عبارت زیر را برآورده میکند:
از آنجا که kmax یک عدد صحیح است، از ≈ بجای = استفاده
کردیم، بنابراین در حالت کلی معادله اصلی پاسخی ندارد. برای یک توزیع پوآسون
که در جزء آخر، حاصل جمع را با بزرگترین جزء آن تخمین زدیم.
برای N = 109 و k=1000 ، یا تقریباً اندازه و درجه
میانگین شبکه اجتماعی جهانی، روابط (3-26) و (3-27) مقدار kmax
= 1,185 را 1185 پیشبینی میکنند که نشان میدهد یک شبکه تصادفی از افراد
بسیار محبوب یا هاب محروم است.
میتوانیم از استدلالی مشابه برای محاسبه درجه مورد انتظار کوچکترین گره
kminاستفاده کنیم. با درنظرگرفتن اینکه که باید حداکثر یک
گره با درجه کمتر از kmin باشد میتوانیم بنویسیم
برای شبکههای اردوش-رنی داریم:
با حل رابطه (3-28) با N = 109 و =1000 مقدار kmin
= 816 را به دست میآوریم.
شکل 3-17 کمترین و بیشترین درجه
تخمین حداکثر درجه یک گره در شبکه، kmax، بهگونهای
انتخاب میشود که حداکثر یک گره وجود داشته باشد که درجه آن بالاتر ازkmax
باشد. این معمولاً برش طبیعی بالایی توزیع درجه نامیده میشود. برای محاسبه آن،
باید kmaxرا طوری تنظیم کنیم که مساحت زیر منحنی توزیع
درجه pk برای k > kmax برابر
1/N باشد، ازاینرو تعداد گرههای مورد انتظار در این ناحیه دقیقاً یک خواهد
بود. برای پیدا کردن کمترین درجه مورد انتظار، kmin، به
شیوه مشابه عمل می¬کنیم..
بخش 3-14
مباحث پیشرفته 3-C
قطعه غولپیکر
در این بخش به معرفی استدلال سولومونوف و رپوپورت [11] و اردوش و رنی در [2]
در خصوص وجود قطعه غولپیکر وقتیکه 〈k〉= 1 است میپردازیم[33].
اجازه دهید کسری از گرهها که در قطعه غولپیکر GC نیستند را با u به مقدار
u = 1 - NG/N نشان دهیم، که NG
اندازه قطعه غولپیکر است. اگر گره i بخشی از GC باشد، باید به گره دیگری مانند
j پیوند خورده باشد، که آنهم جزئی از GC است. بنابراین اگر i بخشی از GC
نباشد، ممکن است به خاطر یکی از دو اتفاق زیر باشد:
پیوندی بین i و j وجود ندارد (احتمال این اتفاق 1-p است).
پیوندی بین i و j وجود دارد، ولی j بخشی از GC نیست (احتمال این pu
است).
بنابراین احتمال کلی اینکه i با توجه به گره j بخشی از GC نباشد برابر با
1-p+pu است. بنابراین احتمال اینکه گره i از طریق هیچ گره دیگری به GC پیوند
نخورده نباشد (1 - p + pu)N - 1 است، زیرا N-1
گره وجود دارند که میتوانند گره i را به GC پیوند دهند. ازآنجاکه u کسری از
گرههایی است که به GC تعلق ندارند، با حل معادله زیر برای هر p و N حل معادله
اندازه قطعه غولپیکر را به کمک NG = N(1 -
u) فراهم میکندبدست میآید. با استفاده از p = 〈k〉/(N
- 1) و با گرفتن لگاریتم از طرفین، برای 〈k〉 « N خواهیم
داشت:
که از بسط سری برای ln(1=+x) استفاده کردیم.
با به توان رساندن طرفین به توان منجر میشود به u = exp[-
〈k〉(1 - u)] بدست میآید. اگر S را برابر با کسری از گرهها
که در قطعه غولپیکر هستند در نظر بگیریم، یعنی S = NG
/ N ، آنگاه S=1-u و (3-31) نتیجه میدهد:
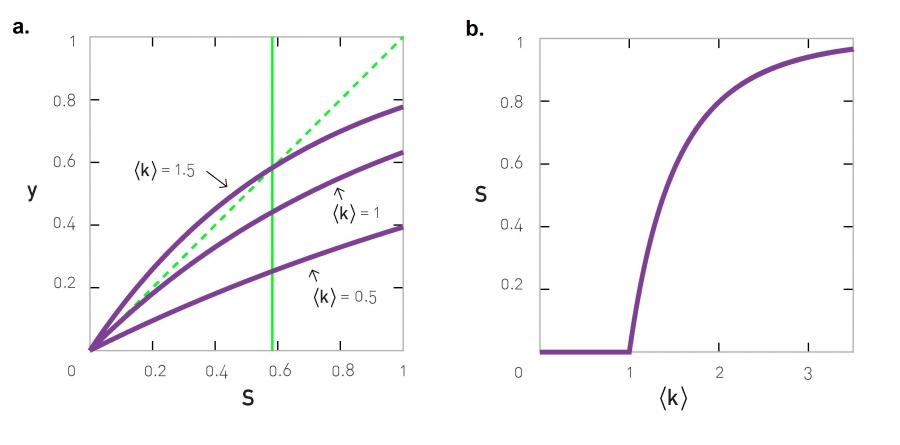
این معادله اندازه قطعه غولپیکر S را با تابعی از〈k〉 ارائه
میدهد(شکل 3-18).
بااینکه رابطه (3-32) آسان به نظر میرسد، راهحل ریاضی بستهای ندارد.
میتوانیم آنرا به کمک سمت راست رابطه (3-32) بهعنوان تابعی از مقادیر مختلف
〈k〉 بهصورت گرافیکی ترسیم کنیم. برای داشتن جواب غیر صفر، منحنی
بهدستآمده باید خطچینی را که نمایانگر سمت چپ رابطه (3-32) است قطع کند.
برای مقادیر کوچک 〈k〉 دو منحنی یکدیگر را تنها در S=0 قطع میکنند، که
بیانگر آن است که برای مقادیر کوچک 〈k〉 اندازه قطعه غولپیکر صفر است.
تنها زمانی که 〈k〉 از یک مقدار آستانه فراتر رود، یک جواب غیر صفر
پیدا میشود.
برای تعیین مقدار 〈k〉 برای وقتیکه داریم به جواب غیر صفر میرسیم
ما نسخهای از رابطه (3-32) مشتق میگیریم استفاده میبینم، زیرا نقطه تغییر
فاز زمانی است که مشتق سمت راست (3-32) همان نسخهبرابر با مشتق سمت چپ (3-32)
را داردباشد، بهعبارتدیگر وقتی
با قرار دادن S=0 درمییابیم که نقطه تغییر فاز در 〈k〉 = 1 است
(مباحث پیشرفته 3-F را هم ببینید).
شکل 3-18 راه حل گرافیکی
سه منحنی بنفشرنگ y = 1-exp[ -‹k›S
] را به ازای ‹k›=0.5, 1, 1.5 نشان میدهند. خط نیمساز مورب سبز
y=S را نشان میدهد، و تقاطع خط مورب و منحنیهای بنفش جواب رابطه (3-32)
را نشان میدهد) است. برای ‹k›=0.5 فقط یک تقاطع در S=0 وجود
دارد، که نشان میدهد قطعه غولپیکری وجود ندارد. منحنی ‹k›=1.5
یک جواب در S=0.583 دارد (خط عمودی سبز). منحنی ‹k›=1 دقیقاً روی
نقطه بحرانی قرار دارد، که نمایانگر جدایی بین دو نظامی است، نظامی که
دریکی جواب غیر صفر برای S وجود دارد و نظامی که در آن تنها یک جواب در S=0
وجود دارد.
‹k›
نشان داده شده است که با رابطه (3-32) همخوانی دارد [33].
بخش 3-15
مباحث پیشرفته 3-D
اندازه قطعات
در شکل 3-7 ما
اندازه قطعه غولپیکر را کاوش کردیم، یک سؤال مهم هنوز بیپاسخ مانده است: برای
یک مقدار مشخص‹k› مشخص،، انتظار داریم شبکه به چند قطعه شکسته
باشدتعداد مورد انتظار مولفه های شبکه چندتاست؟ اندازه و توزیع آنها چیست؟ هدف
این بخش بحث درباره این موضوعات است.
توزیع اندازه قطعه
برای یک شبکه تصادفی احتمال اینکه یک گرهای که به صورت تصادفی انتخابشده باشد
متعلق به قطعهای با اندازه S باشد (که با قطعه غولپیکر GC فرق دارد) برابر
است با [33]:
با جایگذاری exp[(S-1) ln(k)] به جای ‹k›s-1 و
استفاده از فرمول استرلینگ :
برای S های بزرگ به دست می آوریم
بنابراین توزیع اندازه قطعه دو مؤلفه دارد: یک جزء s-3/2که
بر اساس قانون توان بهآرامی کاهش مییابد ، و یک جزء نمایی e-(‹k›-1)s+(s-1)ln‹k›که
بهسرعت کاهش مییابد. با توجه به اینکه جزء نمایی برای S های بزرگ غلبه
میکند، رابطه (3-35) پیشبینی میکند که قطعات بزرگ به وجود نمیآیند. در نقطه
بحرانی، ‹k› = 1، همه جزءهای نمایی کنار زده میشوند، بنابراین ps
از قانون توان پیروی میکند:
چون قانون توان نسبتاً بهآرامی کاهش مییابد، در نقطه بحرانی انتظار داریم
خوشههایی با اندازههایی بسیار متفاوت را مشاهده کنیم، این ویژگی با رفتار یک
سیستم در حال تغییر فاز سازگار است (مباحث پیشرفته 3-F). این پیشبینیها در
شبیهسازی عددی که در شکل 3-19 نشان داده شدهاند، نیز تأیید شده است.
شکل 3-19.
شکل 3-19 توزیع اندازه قطعات
توزیع اندازه قطعه psدر شبکه تصادفی، بدون قطعه غولپیکر
(a)-(c) ps برای مقادیر مختلف ‹k› و
N ، نشان میدهند که، ps برای N های بزرگ به سمت
پیشبینی رابطه (3-34) همگرا میشود.
(d) ps برای N = 104، برای
‹k› های مختلف نمایش داده شده است. اگرچه برای ‹k› ‹ 1 و
‹k› › 1 توزیع ps شکل نمایی دارد، درست در
نقطه بحرانی ‹k› = 1 توزیع از قانون نمایی رابطه (3-36) پیروی
میکند. خط ممتد سبزرنگ به رابطه (3-35) مربوط است. اولین مطالعه عددی
توزیع اندازه قطعه در شبکههای تصادفی در سال 1998 و پیش از افزایش انفجاری
محبوبیت شبکههای پیچیده انجام شد [34].
اندازه قطعه میانگین
محاسبات همچنین مشخص میکنند که اندازه میانگین قطعه (دوباره تأکید میکنیم،
بدون درنظرگرفتن قطعه غولپیکر) از رابطه زیر پیروی میکند [33]:
برای ‹k› ‹ 1 قطعه غولپیکر وجود ندارد (NG =
0)، بنابراین رابطه (3-37) به صورت زیر نوشته می¬شود:
که وقتی درجه متوسط به نقطه بحرانی ‹k› = 1 نزدیک میشود، واگرا
میشود. بنابراین وقتی به نقطه بحرانی نزدیک میشویم، اندازه خوشهها افزایش
مییابد که نشانهای از ظهور قطعه غولپیکر را در ‹k› = 1 اعلام
میکند. شبیهسازیهای عددی این پیشبینی را تأیید میکنند (شکل
3-20).
برای تعیین اندازه میانگین قطعه میانگین برای ‹k› › 1 به کمک رابطه
(3-37)، ابتدا باید اندازه قطعه غولپیکر را محاسبه کنیم.این روند می تواند به
صورت خودسازگار انجام شود، زیرا برای ‹k› › 1 هرچه خوشها توسط قطعه
غول پیکر جذب می شوند، اندازه قطعه میانگین کاهش پیدا می کند
در نظر داشته باشید که رابطه (3-37) اندازه قطعهای را پیدا میکند که یک
گرهای که بصورت تصادفی انتخاب شده تصادفی متعلق به آن است. این نگرش دچار
سوگیری استاین معیار بیطرفانه نیست، زیرا شانس تعلق داشتن به یک قطعه بزرگتر
بیشتر از شانس تعلق داشتن به یک قطعه کوچکتر است. سوگیری برحسب اندازه خوشه S
خطی است. اگر این سوگیری را درست بگیریماصلاح کنیم، اندازه میانگین جزءهای کوچک
را به دست میآوریم که اگر میخواستیم برای هر خوشه جداگانه محاسبه کنیم و در
آخر میانگین بگیریم نیز به همان اندازه میرسیدیم [33]
در شکل 3-20 تعدادی شکل درتایید (3-39) ارائه شده است.
شکل 3-20
اندازه قطعه میانگین
این شکل میانگین اندازه قطعات ‹s›که یک گرهای دلخواه به آن تعلق دارد را نشان میدهد. منحنی بنفش حاصل رابطه (3-39) و منحنی سبز میانگین اندازه کلی یک جزء‹s'› را طبق رابطه (3-37) نشان میدهند[33].
میانگین اندازه خوشه در یک شبکه تصادفی را نشان میدهد. یک گره را انتخاب کرده و اندازه خوشهای را که به آن تعلق دارد تعیین کردیم. این اندازهگیری سوگیری دارد، زیرا هر یک از اجزای با اندازه S، به تعداد S بار شمارش میشوند. هرچه N بزرگتر شود، دادههای عددی به پیشبینی رابطه (3-37) نزدیکتر میشوند. همانطور که پیشبینیشده بود، ‹s› در نقطه بحرانی ‹k›=1، یک تغییر فاز را نشان میدهدواگراست (موضوعات پیشرفته 3-F).
) میانگین اندازه خوشه در یک شبکه تصادفی را نشان میدهد، با این تفاوت که هر یک از مؤلفهها فقط برای یکبار انتخاب شدهاند تا سوگیری اندازهگیری در بخش (b) تصحیح شود. هرچقدر N بزرگتر میشود ، دادههای عددی به پیشبینی رابطه (3-39) نزدیکتر میشوند.
بخش 3-16
مباحث پیشرفته 3-E نظام یکپارچه (تمام-متصل)
برای محاسبه ‹k› در حالتی که اکثر گرهها جزئی از قطعه غولپیکر هستند، احتمال اینکه یک گره که به صورت تصادفی انتخابشده، پیوندی به با قطعه غولپیکر نداشته باشد را محاسبه میکنیم، که برابر است با (1-p)NG≈(1-p)N، زیرا در نظام یکپارچهNG ≃ N. :
تعداد مورد انتظار چنین گرههای ایزولهای منفردی با استفاده از تقریب 1-x/n)n≈e-x
که برای n بزرگ معتبر است، برابر است با. If we make p اگر p را
بهاندازه کافی بزرگ در نظر بگیریم، به نقطهای میرسیم که تنها یک گره پیوندش
از قطعه غولپیکر قطعشده است. در این نقطه IN = 1 خواهد
بود، بنابراین از طبق رابطه (3-40) خواهیم داشت: Ne-Np=1. بنابراین
مقدار p درجایی که نزدیک است به نظام یکپارچه کاملا همبند وارد شویم عبارت است
از:
که برحسب ‹k› به رابطه (3-14) منجر خواهد شد.
بخش 3-17
مباحث پیشرفته 3-F
تغییر فاز
Tظهور قطعه غولپیکر در ‹k›=1 در مدل تصادفی شبکه یادآور تغییر فاز
است، پدیدهای که بیشتر در شیمی و فیزیک موردمطالعه قرارگرفته است[35]. دو مثال
را در نظر بگیرید:
تبدیل یخ-آب (شکل
3-21a): در دمای بالا مولکولهای H2O درگیر حرکات پراکنده
میشوند، گروههای کوچک تشکیل میدهند و بعد از هم جدا میشوند تا با
مولکولهای دیگر تشکیل گروه دهندجمع شوند. اگر این مولکولها سرد شوند، در
دمای 0˚C ناگهان این حرکات پراکنده متوقف میشود و بلور منظم و سفت یخ
تشکیل میشود.
جاذبه (شکل
3-21b): در فلزات فرو مغناطیسی مثل آهن در دمای بالا چرخشهای اتمها
در جهات دلخواه و تصادفی میچرخنداست. زیر اما در یک دمای بحرانی Tc
چرخش همهاتمها در یکجهت واحد میچرخند است که درنتیجهو فلز تبدیل به یک
آهنربا میشود.
یخ زدن مایع و به وجود آمدن میدان مغناطیسی مثالهایی از تغییر فاز هستند،
که نمایانگر تغییر از بینظمی به نظم است. در مقایسه بانظم بینظیر بلور یخ، آب
مایع فاقد نظم است. بهطور مشابه، در ماده فرومغناطیسی جهت های چرخش متفاوت در
دمای زیرTc به چرخش در یک جهت تبدیل می شوند.چرخشهای با
جهت چرخش متفاوت در ماده فرو مغناطیسی در دمای زیر Tc به
نظم قوی غالب در جهت چرخش تبدیل میشود.
بسیاری از ویژگیهای سیستمهایی که در حال تغییر فاز هستند، سراسری هستند.
یعنی الگوهای کمّی مشابهی در گستره وسیعی از سیستمها مشاهدهشده است، از سرد
شدن ماگما و تبدیل آن به صخره گرفته تا تبدیل ماده سرامیک به ابررسانا. علاوه
بر این، در نزدیکی نقطه تغییر فاز، که به آن نقطه بحرانی میگویند، بسیاری از
کمیتهای موردتوجه، از قانون- توان پیروی میکنند.
مساله مشاهدهشده در نزدیکی نقطه بحرانی در ‹k› = 1 از بسیاری جهات
مشابه تغییر فاز است:
تشابه بین شکل شکل 3-7a و نمودار مغناطیسی شدن در 3-21b تصادفی نیست، هردو آنها تغییر از بینظمی به نظم را نشان میدهند. در شبکههای تصادفی، وقتی ‹k› از ‹k› = 1 فراتر میرود، منجر به ظهور یک قطعه غولپیکر میشود.
همینطور که به نقطه انجماد نزدیک میشویم، کریستالهای یخ با اندازههای متفاوت مشاهده میشوند، همین موضوع در خصوص دامنه مغناطیسی اتمهایی با چرخشهای همجهت نیز صادق است. توزیع اندازه کریستالهای یخ یا دامنههای مغناطیسی از قانون- توان پیروی میکند. بهطور مشابه وقتی برای ‹k› › 1 یا ‹k› ‹ 1 اندازه خوشهها از یک توزیع نمایی پیروی میکنند، درست در نقطه تغییر فاز ps از قانون توان پیروی میکند، که نشاندهنده وجود همزمان قطعاتی با اندازههای متفاوت است.
در نقطه بحرانی اندازه میانگین کریستالهای یخ یا دامنه مغناطیسی تغییر میکندمتفاوت میشود، که اطمینان میدهند کهتضمین میکند کل سیستم در حال به یکتکه یخ واحد تبدیل به یکتکه یخ واحد استمیشود یا اینکه تمام چرخشها در یکجهت واحد انجام میشوند. بهطور مشابه در یک گراف تصادفی میانگین اندازه خوشه ‹s› وقتی به ‹k› = 1 نزدیک میشویم تغییر میکند
(شکل 3-20 ).
شکل 3-21 تغییر فاز
تغییر فاز آب-یخ
پیوندهای هیدروژن که مولکولهای آب را در کنار هم نگه میدارند (نقطهچین) ضعیف هستند و بهطور مداوم در حال شکسته شدن و شکلگیری مجدد هستند و ساختارهای محلی جزئی منظم شده (سمت چپ) را حفظ میکنند. نمودار فاز فشار-دما (بخش مرکزی) نشان میدهد که با پایین آمدن دما، آب تحت فاز گذار قرار میگیرد و از مایع (بنفش) به فاز جامد (سبز) منتقل میشود. در فاز جامد، هر مولکول آب با چهار مولکول دیگر پیوند سختی برقرار میکند و یک توری منظم یخ (سمت راست) تشکیل میدهد .
تغییر فاز مغناطیسی
در مواد فرو مغناطیسی، گرایش مغناطیسی اتمهای منفرد (چرخشها ) میتواند در دو جهت متفاوت باشد. در دماهای بالا بهطور تصادفی جهت خود را انتخاب میکنند (پانل شکل سمت راست). در این حالت بینظم، خاصیت مغناطیسی کل سیستم (m = ΔM/N که در آن ΔM تعداد چرخشهای رو به بالا منهای تعداد چرخشهای رو به پایین است) صفر است. شکل میانی نشان میدهد که با پایین آمدن دمای T، در نقطه T= Tc تغییر فاز اتفاق می افتد و خاصیت مغناطیسی ظاهر میشود. پایین آمدن بیشتر T اجازه میدهد تا m به 1 همگرا شود. در این مرحله، تمام چرخشها به صورت منظم و در یکجهت انجام میشوند (شکل سمت چپ).
بخش 3-18
مباحث پیشرفته 3-G
اصلاحات جهان کوچک
معادله (3-18) تنها تخمینی برای قطر شبکه ارائه میدهد، که برای N خیلی بزرگ و d کوچک معتبر است. در عوض، درست در زمانی که ‹k›d بهاندازه شبکه، N، نزدیک میشود رشد ‹k›d باید متوقف شود، چون دیگر گرهای نداریم تا گسترش ‹k›d ادامه پیدا کند. چنین تأثیرات محدودی منجر به اصلاحاتی در رابطه (3-18) میشوند. برای شبکه تصادفی با درجه میانگین ‹k›، رابطه زیر تخمین بهتری برای قطر شبکه ارائه می دهد[36]:
که در آن W-تابع لامبرت برحسب W یا W(z) معکوس اصلی f(z) = z exp(z)(z) یا جزء اول در سمت راست رابطه (3-18) است، درحالیکه جزء دوم تصحیحی است که به میانگین درجه بستگی دارد. این اصلاح، قطر را افزایش میدهد، با در نظرگرفتن این واقعیت که وقتی به قطر شبکه میرسیم، تعداد گرهها باید کندتر از افزایش یابند. اگر سایر محدودیتهای رابطه (3-42) را در نظر بگیریم، گرایش بزرگی این اصلاح بیشتر آشکار میشود.
در حالت حدی ‹k› → 1 میتوانیم W-تابع لامبرت را برای بدست آوردن قطر، برحسب W حساب کنیم، و به رابطه زیر دست پیدا کنیم[36]:
بنابراین درزمانی که قطعه غولپیکر ظاهر میشود، قطر سه برابر اندازهای است کهپیشبینی انجام شده توسط رابطه (3-18) به دست آمده بوداست. دلیل این امر این است که در نقطه بحرانی ‹k› = 1 شبکه یک ساختار شبه درختی دارد که شامل زنجیرههای طولانی ندرتا حلقه دارد به همراه هر نوع حلقهای است کهو این پیکربندی موجب افزایش dmax میشود.
در حالت حدی ‹k› → ∞، که مربوط به یک شبکه بسیار چگال است، رابطه (3-42) تبدیل میشود به
بنابراین اگر ‹k› افزایش یابد، جزء دوم و سوم ناپدید میشوند و نتیجه رابطه (3-42) به نتیجه رابطه (3-18) همگرا میشود.
بخش 3-14
مراجع
[1] A.-L. Barabási. Linked: The new science of networks. Plume
Books, 2003.
[10] E. N. Gilbert. Random graphs. The Annals of Mathematical Statistics,
30:1141-1144, 1959.
[11] R. Solomonoff and A. Rapoport. Connectivity of random nets. Bulletin
of Mathematical Biology, 13:107-117, 1951.
[12] P. Hoffman. The Man Who Loved Only Numbers: The Story of Paul
Erdős and the Search for Mathematical Truth. Hyperion Books, 1998.
[13] B. Schechter. My Brain is Open: The Mathematical Journeys of
Paul Erdős. Simon and Schuster, 1998.
[14] G. P. Csicsery. N is a Number: A Portait of Paul Erdős,
1993
[15] B. Bollobás. Random Graphs. Cambridge University Press,
2001.
[16] L. C. Freeman and C. R. Thompson. Estimating Acquaintanceship.
Volume, pg. 147-158, in The Small World, Edited by Manfred Kochen
(Ablex, Norwood, NJ), 1989.
[17] H. Rosenthal. Acquaintances and contacts of Franklin Roosevelt.
Unpublished thesis. Massachusetts Institute of Technology, 1960.
[18] L. Backstrom, P. Boldi, M. Rosa, J. Ugander, and S. Vigna. Four
degrees of separation. In ACM Web Science 2012: Conference Proceedings,
pages 45−54. ACM Press, 2012.
[19] R. Albert and A.-L. Barabási. Statistical mechanics of complex
networks. Reviews of Modern Physics, 74:47-97, 2002.
[20] I. de Sola Pool and M. Kochen. Contacts and Influence. Social
Networks, 1: 5-51, 1978.
[21] H. Jeong, R. Albert and A. L. Barabási. Internet: Diameter of the
world-wide web. Nature, 401:130-131, 1999.
[22] S. Lawrence and C.L. Giles. Accessibility of information on the Web
Nature, 400:107, 1999.
[23] A. Broder, R. Kumar, F. Maghoul, P. Raghavan, S. Rajagopalan, R.
Stata, A. Tomkins, and J. Wiener. Graph structure in the web. Computer
Networks, 33:309–320, 2000.
[24] S. Milgram. The Small World Problem. Psychology Today, 2: 60-67,
1967.
[25] J. Travers and S. Milgram. An Experimental Study of the Small World
Problem. Sociometry, 32:425-443, 1969.